Spark on Hive实现APP渠道分析
背景
最近在做APP投放渠道分析,就是Android应用投放到应用市场,所谓渠道就是huawei,xiaomi,yingyongbao之类,运营人员根据数据分析渠道的下载安装情况、各个渠道的投放效果。
需求
完成一个Android渠道分析的展示面板,包含以下指标:
- APP总新增激活数量
- 按渠道划分的新增数量
- 各渠道的新增变化走势图(以小时为单位)
- 品牌占比
- 操作系统占比
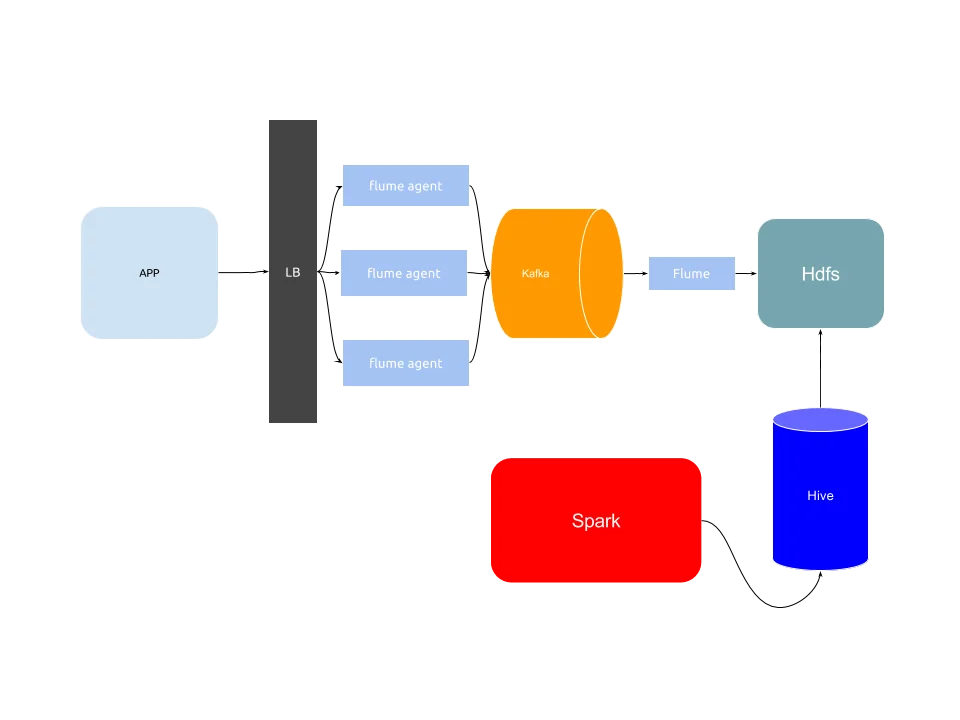
架构
数据
APP激活时上报给服务端数据,Flume处理数据并将数据发送到Kafka。
数据格式
客户端上报对JSON格式更加友好,所以这里选择使用JSON格式,格式定义一方面需要考虑客户端的开发成本,一方面需要考虑日后的拓展性,所以最直接的方法是统一固定的字段,将根据事件所变化的内容放到拓展字段里去,拓展字段是Map类型,可以支持各种拓展的形式。
数据内容
以此次渠道分析为例,客户端需要上传客户端的渠道、APP版本、设备标志符、设备型号等信息,更详细的如Geo信息,如果想获得更好的数据展示效果,可以上传,但在此场景可以不需要,这些是主动上报的部分。还有一部分内容是需要在服务端获取的,例如设备IP,为了之后的地理展示,可以使用MaxMind公司的IP与城市对应的数据库进行地理解析。
数据处理
flume接受到客户端的数据之后,需要对数据进行解析JSON,并且获得用户IP、分析Geo Location做一些轻量级的处理,因为这个部分是在前端flume做的,这个部分的flume重点是逻辑要轻,重要的是吞吐量高和延迟低。
接下来前端flume把处理完的数据按照事件名发送到Kafka同名的topic中,后端flume消费Kafka并将消息转存到Hdfs中。
数据持久化
将数据从Hdfs持久化到Hive,一方面是更节省空间,一方面是更有利于Spark进行查询。
这里持久化到Hive的方法,可以有几种:
- Flume直接读取Kafka的数据并存储到Hive,这是由Flume的Hive Sink实现的,数据持久化到Hive Transaction表,是Hive 0.13引入的,支持ACID。
- Flume读取数据到Hdfs,支持配置文件路径,可以根据时间来划分存储路径,之后可以定期使用Hive加载数据,将数据存储到Hive中去。
第一种方法,相对来说配置简单,省去了中间一步转储的过程。第二种方法,相对繁琐,但是之后会有一个好处。
下面是设备注册表device_registration的schema
1 | CREATE TABLE `bi.device_registration`( |
这里要提一下,为什么有了time这个unix时间戳,还需要ts这个timestamp类型的时间,实际上是为了之后的查询工具Superset需要使用来实现按时间查询。
计算
这里的计算每小时运行一次,从Hive中读取过去一个小时的设备激活原数据,与device_registration进行比对,将未出现在device_registration中的设备信息加入。
这里可以使用JOIN来实现,Spark数据表之间的Join方式有多种,inner, cross, outer, full, full_outer, left, left_outer, right, right_outer, left_semi, left_anti
这里场景适合使用left_anti,因为是取不在这个集合的设备信息。
这里还要注意,因为时间区间内的数据有可能会有重复,所以需要取时间较早的那条,这里用到了groupByKey和reduceGroups,具体是
1 | deviceInfos.as[Device] |
查询
查询引擎使用Presto,配置Hive Connector,实时搜索数据。刚才上面提到数据持久化Hive中的两种方法,其中支持事务的表不可用于Presto的查询,因为Hive Transaction表的数据格式未被Presto支持(详见Implement Hive ACID table support)。
直接查询
通过上一步的device_registration表,我们可以通过时间维度进行查询。
直接查询就是查询raw data,数据更加丰富。这里以“按渠道划分的新增数量”为例,
1 | SELECT "channel" AS "channel", |
预先计算
预先计算就是将图表展示需要的数据结果提前计算存储到数据库,查询的时候直接就可以从结果表中查询。
预先计算是用空间换时间,损失一些灵活性,不如查询raw data时可以自由定制查询。每次新增查询对于预先计算来说都需要新增加计算逻辑。随着数据量的增大,预先计算不可避免。
优化查询速度
运行一段时间后,查询速度明显变慢,查看Hdfs上的hive目录发现数据表内的小文件多达几百上千,这是由于Spark处理完数据并写入Hive会产生非常多的bucket,与数据条数成正比,写入成本低却增加了读数据的成本,这样当数据查询时,由于Hdfs上的小文件非常之多,I/O花费很大,导致整体查询速度下降迅速,这里想办法将文件进行合并,减少文件数量。
通过使用Hive执行compaction,方法比较取巧,就是在每次计算完数据之后,运行Hive脚本,通过复制数据库,Hive会自动将文件数量压缩:
1 | CREATE TABLE bi.device_registration_compact AS SELECT * from bi.device_registration; |
将Hdfs上的文件数量降低到个位数,查询也在秒级完成,这种方法只适用于数据量不大的情况,目前记录条数在1M以内的查询速度在秒级,之后依然会考虑使用其它方案改良。
展示
Superset是Airbnb开源的图表展示工具,不仅支持很多后端查询引擎,并且有许多成熟的图表展示,更可贵的是拥有用户权限管理。