Implement zero downtime HTTP service rollout on Kubernetes
You might have encountered some 5xx errors during http service rollout on Kubernetes and wonder how to make it more reliable without these errors, this article will first explain where this errors come from and how to fix them and implement zero downtime.
Sometimes you can’t see downtime because it’s hidden
First, I would like to share an interesting case before we setup the zero downtime rollout, the client is accessing the service through envoy and fortunately we have x-envoy-retry-on on connect-failure and gateway-error in envoy, so the client didn’t see any 500 or 503 caused by the service rollout, envoy did all the work to “hide” these errors.
We don’t spend too much time solving the real rollout issue thanks to Envoy, but it’s not a liable solution, the errors are just hidden by some retries. When the envoy configuration is not set correctly, the client will suffer from this.
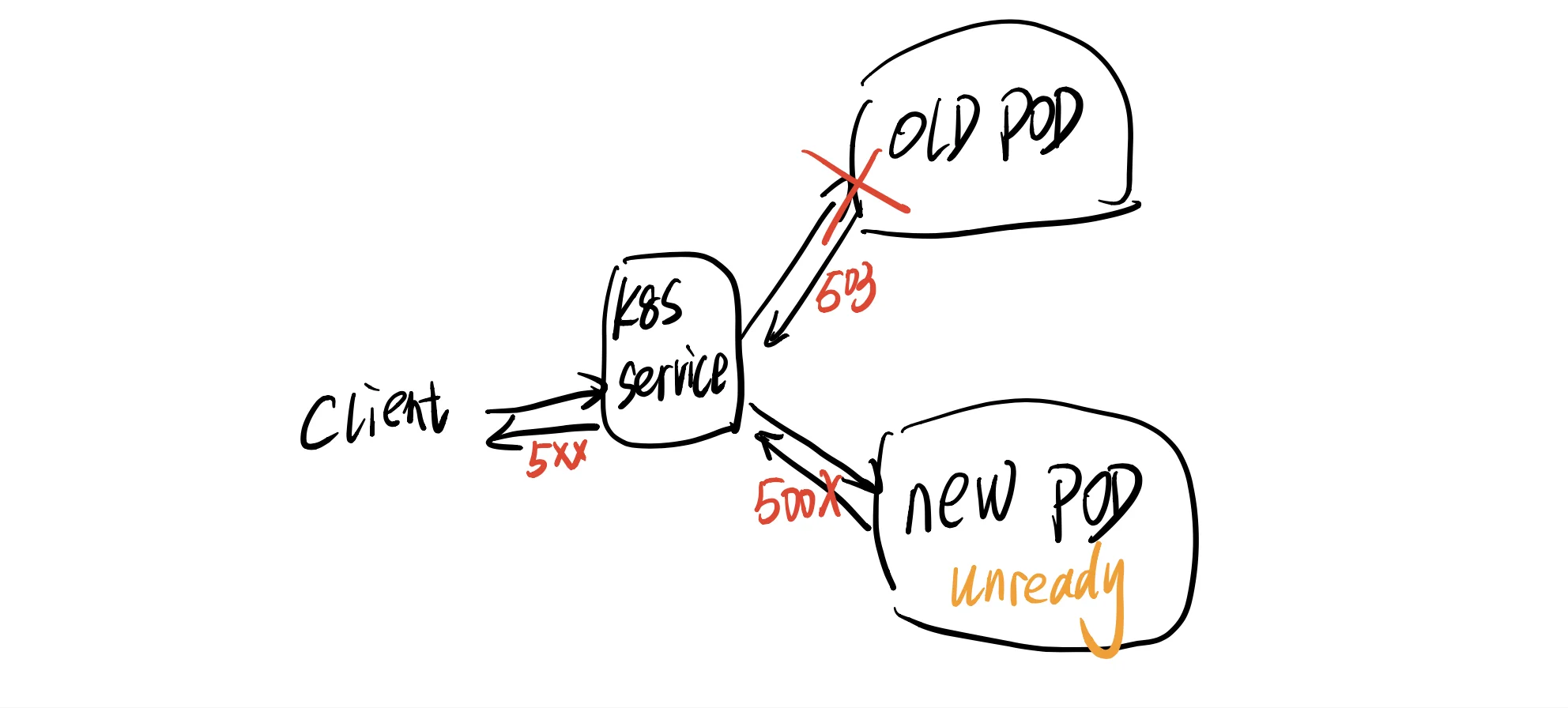
When does it respond 5xx?
According to the Pod lifecycle, there will be two moments when the service can return 5xx (it may be 503 or 500).
- The moment when the old Pod is killed.
- The moment when the new Pod is provisioned.
500 error
When a new Pod is created and it receives traffic before it’s ready, it will respond 500 to the clients. In this case, we need an accurate readiness check on the Pod, only if the readiness is okay, the Pod starts taking traffic.
Ensure application container is ready
The application pod has readiness check, the developer needs to implement a good readiness to ensure the application can start to serve traffic.
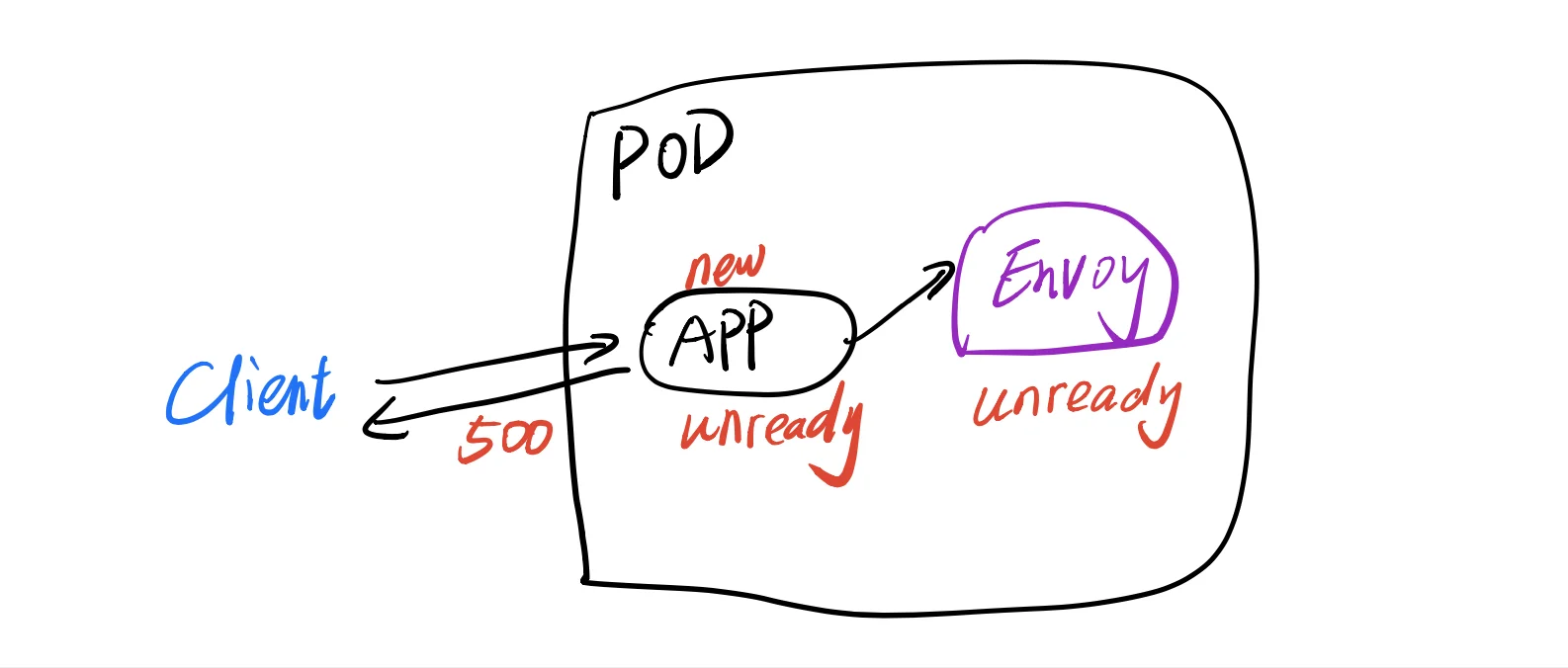
A basic readiness can be the application HTTP server is started, you can also check the hard dependencies of the application are ready. For example, MySQL instances are connected, Redis, Cassandra, Kafka are healthy to connect.
1 | readinessProbe: |
It means when the application is ready, it will wait for initialDelaySeconds (5 seconds in this case) and test the healthcheck API, if it’s healthy then the Pod will be marked ready and it will receive traffic.
Ensure the sidecars are ready.
The readiness of the sidecar container is needed and should be set up the same way as the application container.
Some service mesh frameworks, like Istio, every Pod has an Envoy sidecar, all of the outbound requests will go through it and Envoy is ready when its route configuration is fetched from Istio controlplane, more importantly, it must be ready before the application.
If your application needs to initialize resources by calling envoy, you might ensure envoy is ready before the application.
503 error
When the pod is killed it may still in the load balancer pool for a short time then it will still receive some requests, or it’s processing some in-flight requests which reached the pod before the pod is killed.
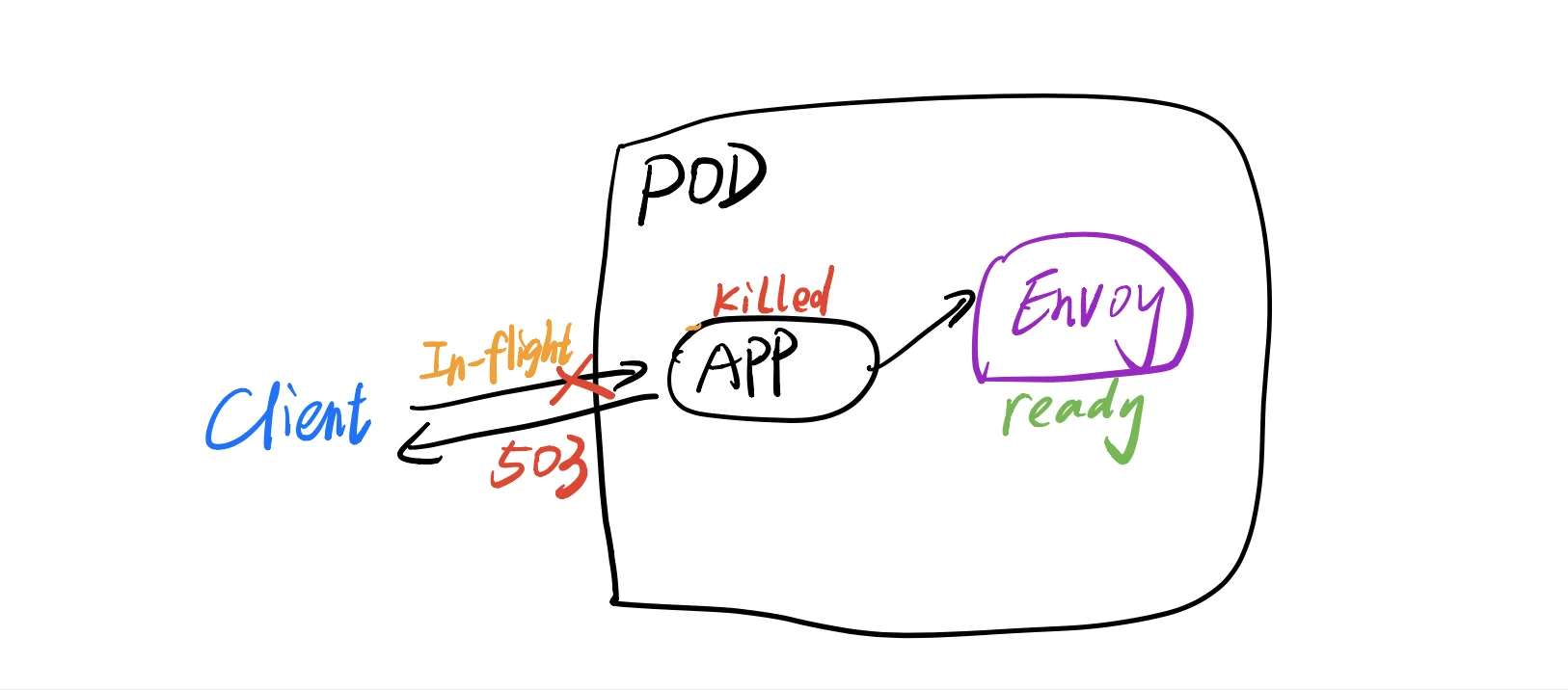
To solve this, we can roughly let the pod wait until it is removed from the LB pool and it finishes all (or most) of the in-flight requests, then it’s safe to shutdown.
1 | lifecycle: |
This means before the application exits, it will wait for 15 seconds, after that Kubernetes will send SIGTERM to the container. During this 15 seconds, it will have time to handle the in-flight requests instead of returning 503. 15 second is only a generic duration which we consider it’s enough for the application to finish all the requests, it could be shorter or longer according to the reality.
More advanced case is your application needs to implement some graceful shutdown, for example, recycle the resources, close the MySQL connections or other tasks, this is something implemented in the application code.
Testing
Before we deploy the Kubernetes configuration to the production environment, we can test in the testing environment. Use loadtest tool to simulate a bunch of requests to the Kubernetes application, randomly kill the pod during the test. After the new pod is ready, check if the responses contain 500 or 503.
Reference
- The Gotchas of Zero-Downtime Traffic /w Kubernetes
- Delaying shutdown to wait for pod deletion propagation