主要介绍一下PHP7对于数组的实现。
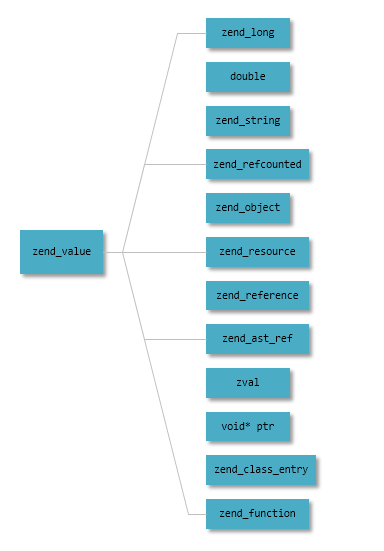
预备知识 PHP的数据类型
zend_long php中的long类型, 在64位机上是64位有符号整数, 不然是32位符号整数。
1 2 3 4 5 6 7 8 9 10 11 #if defined(__x86_64__) || defined(__LP64__) || defined(_LP64) || defined(_WIN64) # define ZEND_ENABLE_ZVAL_LONG64 1 #endif #ifdef ZEND_ENABLE_ZVAL_LONG64 typedef int64_t zend_long;#else typedef int32_t zend_long;#endif
double 双精度浮点数
zend_refcounted 引用计数类型, 记录引用次数, 以及u用于存储元素类型信息type字段(如is_string, is_array, is_object等), 标明对象是否调用过free, destructor函数的flags, 记录GC root number (or 0) and color的gc_info字段(详情见php的zend_gc.h及zend_gc.c).
1 2 3 4 5 6 7 8 9 10 11 12 13 struct _zend_refcounted { uint32_t refcount; union { struct { ZEND_ENDIAN_LOHI_3( zend_uchar type, zend_uchar flags, uint16_t gc_info) } v; uint32_t type_info; } u; };
zend_string 字符串类型, 带有引用计数, 和string的hash值h, 避免每次需要计算, 字段长度len, 以及val用来索引字符串, 这里tricky地避免了2次malloc内存.
1 2 3 4 5 6 7 8 typedef struct _zend_string zend_string ;struct _zend_string { zend_refcounted gc; zend_ulong h; size_t len; char val[1 ]; };
zend_object 1 2 3 4 5 6 7 8 9 typedef struct _zend_object zend_object ;struct _zend_object { zend_refcounted gc; uint32_t handle; zend_class_entry *ce; const zend_object_handlers *handlers; HashTable *properties; zval properties_table[1 ]; };
zend_resource 1 2 3 4 5 6 struct _zend_resource { zend_refcounted gc; int handle; int type; void *ptr; };
zend_reference 1 2 3 4 struct _zend_reference { zend_refcounted gc; zval val; };
zend_array 详细见下文具体实现.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 typedef struct _zend_array zend_array ;typedef struct _zend_array HashTable ;struct _zend_array { zend_refcounted gc; union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar nApplyCount, zend_uchar nIteratorsCount, zend_uchar reserve) } v; uint32_t flags; } u; uint32_t nTableMask; Bucket *arData; uint32_t nNumUsed; uint32_t nNumOfElements; uint32_t nTableSize; uint32_t nInternalPointer; zend_long nNextFreeElement; dtor_func_t pDestructor; };
位运算 给出一个上限Max, 利用位运算求出指定N的表达式-(Max-(N % Max))的值.
1 2 3 4 uint32_t max = 2 ;uint32_t mask = (uint32_t )-max; uint32_t n = 12345678 ;int32_t answser = (int32_t )(n | mask);
散列表 散列表原理维基百科
局部性原理 空间局部性, 时间局部性
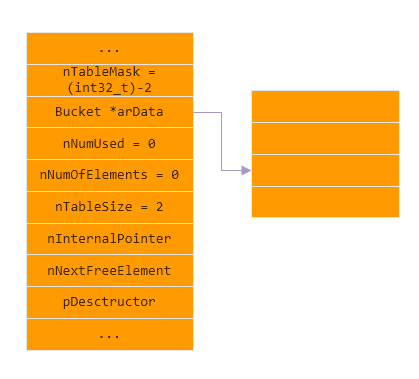
具体实现 初始化
arData指针指向的内存, 是真实数据的起始地址, 在邻近的低址内存是存储hash值到真实数据地址的映射表, 这个映射表是uint32_t类型的数组, 大小相同于nTableSize, 这样最好情况下, 每个hash值都能映射一个真实数据.
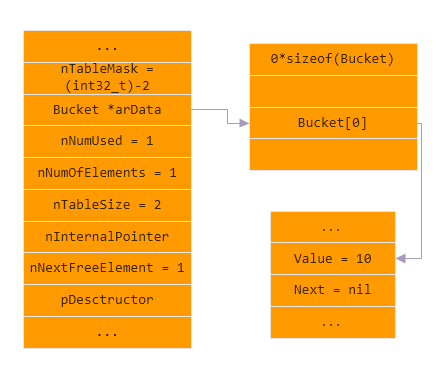
插入 插入key为$key1, $key1.hash为0, 值为10的元素
上文提到的位运算就是应用在插入元素场景, 由于arData指向的是真实数据的起始地址, 而索引信息(即存储hash值到真实数据的映射)处于arData更低地址, 那么要更新索引信息, 就需要计算出-(nTableSize-(nHash % nTableSize)), nHash就是键的hash值, 例如向大小为2的数组, 插入hash值为0的元素, 那么索引到hash值为0的区域就是((uint32_t*)arData)-(2-(0%2)), 如图, 将hash值为0的数据偏移0*sizeof(Bucket)存储到了((uint32_t*)arData)-2.
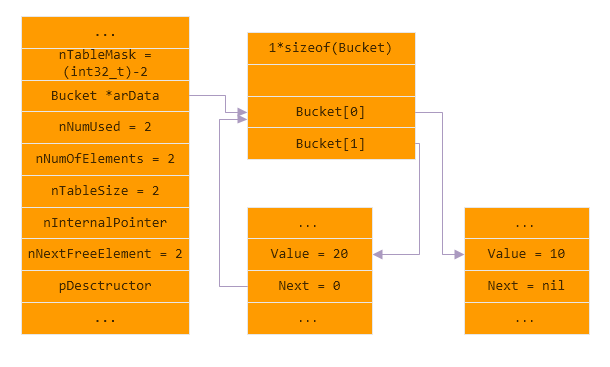
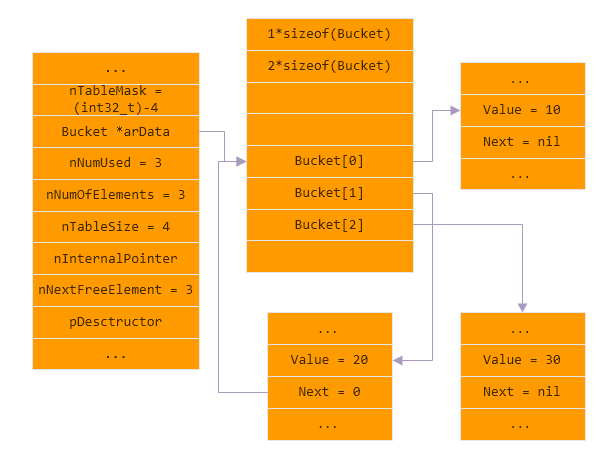
哈希冲突 插入key为$key2($key2 != $key1), $key2.hash为0, 值为20的元素, 造成哈希冲突
数组拓容 插入key为$key3, $key3.hash为1, 值为30的元素, 造成数组的load factor过高, 触发拓容
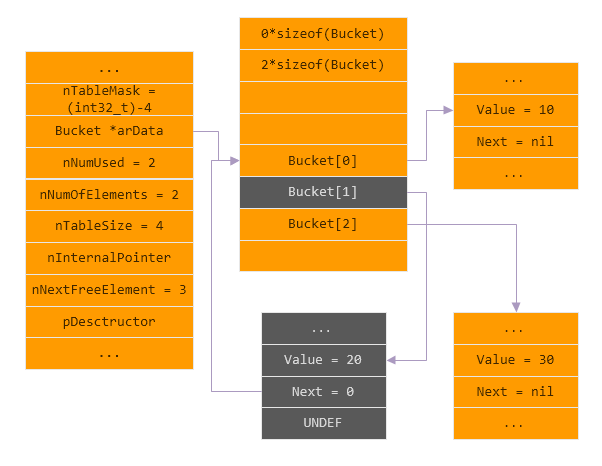
删除 删除key为$key2的元素
1 2 <?php delete $arr [$key2 ];
遍历 1 2 3 4 5 6 7 8 9 <?php foreach ($arr as $v ) { print $v . "\n" ; }
直接遍历arData, 最大边界为arData+nNumUsed, 跳过被UNDEF的元素.
与历史版本比较 改进 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 typedef struct _hashtable { uint nTableSize; uint nTableMask; uint nNumOfElements; ulong nNextFreeElement; Bucket *pInternalPointer; Bucket *pListHead; Bucket *pListTail; Bucket **arBuckets; dtor_func_t pDestructor; zend_bool persistent; unsigned char nApplyCount; zend_bool bApplyProtection; #if ZEND_DEBUG int inconsistent; #endif } HashTable;
连续的内存, 更高的效率Bucket **arBuckets分配一块二维Bucket数组存放键值, 与7.0的预分配连续内存的做法不同, 每次需要插入元素都要申请一块sizeof(Bucket)的内存, 更容易造成内存碎片, 以及低效率;
更小的数据结构, 更优美的实现Bucket *pListHead以及Bucket *pListTail这两个头尾指针, 本来是为了实现数组 特性, 实现正反序遍历等功能, 而7.0既然已经是连续的一块内存, 那么直接从Bucket *arData下标0处, 到达边界arData+nNumUsed就可以实现这个功能.
良好的局部性
可以说这个7.0版本对PHP数组的优化是非常成功的, 除此之外, 对于其他的数据结构7.0也是有”瘦身”优化, 对于整个效率和内存占用有比较明显的改善.