levelDB里缓存实现
leveldb的缓存机制
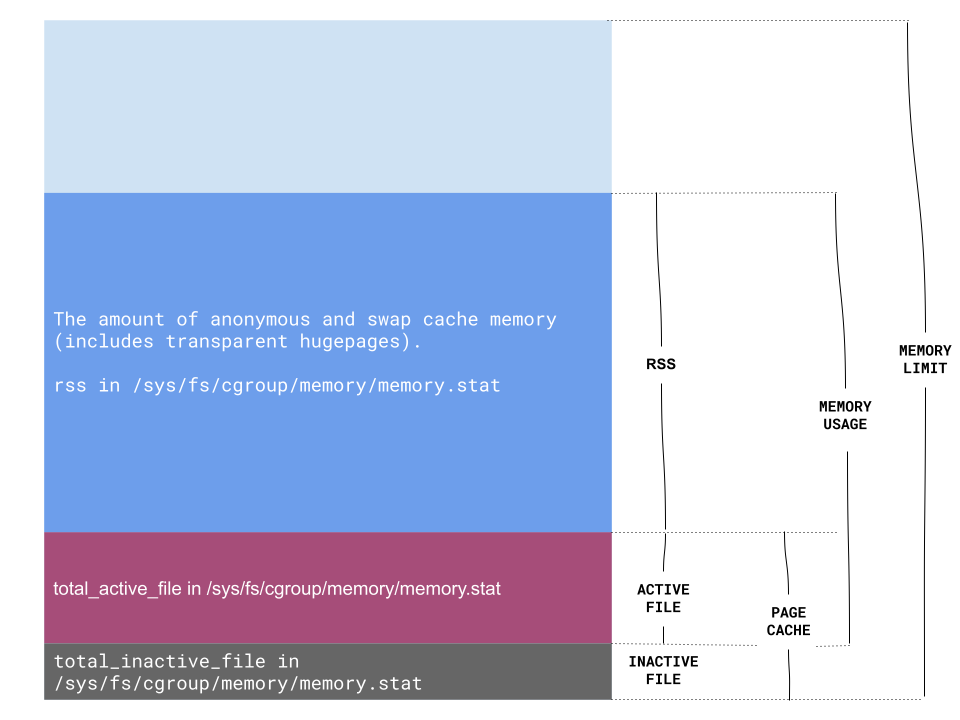
leveldb采用LRU机制, 利用键的哈希值前n位作为索引, 将要插入的键值对分派到指定的缓存区, 当缓存区的使用率大于总容量后, 优先淘汰最近最少使用的缓存, 独立的缓存区总量为2^n .
初始化ShardedLRUCache
- 设置初始缓存容量, 并设置16个子分区的容量.
1
2
3
4
5
6
7
8
9static const int kNumShardBits = 4;
static const int kNumShards = 1 << kNumShardBits;
explicit ShardedLRUCache(size_t capacity)
: last_id_(0) {
const size_t per_shard = (capacity + (kNumShards - 1)) / kNumShards;
for (int s = 0; s < kNumShards; s++) {
shard_[s].SetCapacity(per_shard);
}
}
新建缓存
- 由key的hash值的前kNumShardBits位作为子缓存区索引, 默认为前4位的索引位, 索引到指定的区, 子缓存区LRUCache接管新建缓存的任务.
1
2
3
4
5
6
7class ShardedLRUCache : public Cache {
...
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
const uint32_t hash = HashSlice(key);
return shard_[Shard(hash)].Insert(key, hash, value, charge, deleter);
} - LRUCache结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// A single shard of sharded cache.
class LRUCache {
public:
LRUCache();
~LRUCache();
// Separate from constructor so caller can easily make an array of LRUCache
void SetCapacity(size_t capacity) { capacity_ = capacity; }
// Like Cache methods, but with an extra "hash" parameter.
Cache::Handle* Insert(const Slice& key, uint32_t hash,
void* value, size_t charge,
void (*deleter)(const Slice& key, void* value));
Cache::Handle* Lookup(const Slice& key, uint32_t hash);
void Release(Cache::Handle* handle);
void Erase(const Slice& key, uint32_t hash);
private:
void LRU_Remove(LRUHandle* e);
void LRU_Append(LRUHandle* e);
void Unref(LRUHandle* e);
// Initialized before use.
size_t capacity_;
// mutex_ protects the following state.
port::Mutex mutex_;
size_t usage_;
// Dummy head of LRU list.
// lru.prev is newest entry, lru.next is oldest entry.
LRUHandle lru_;
HandleTable table_;
};
LRUCache才是真正具有缓存功能的结构, capacity_表示它的最大容量, mutex_规范各线程互斥地访问, usage_标志缓存中已用容量, lru_作为哑节点, 它的前节点是最新的缓存对象, 它的后节点是最老的缓存对象, table_是用来统计对象是否被缓存的哈希表.
LRUCache缓存生成
- 缓存的基础节点是
LRUHandle, 储存节点的(键, 值, 哈希值, next, prev节点, 销毁处理函数等)信息. 综合上面的LRUCache结构也看到, 实际上, 缓存节点是双向列表存储,LRUHandle lru_这个哑节点用来分隔最常更新的节点和最不常更新节点. - 当要将缓存节点插入缓存区, 先由哈希表判断缓存是否已存在, 若存在, 将其更新至最常更新节点; 若不存在, 则插入为最常更新节点. 同时更新哈希表
HandleTable table_. - 这里的HandleTable实现并没特殊之处, 我看是采用键哈希策略进行哈希, 如果键冲突则以链表进行存储.
- 利用二级指针对链表进行插入.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == NULL ? NULL : old->next_hash);
*ptr = h;
if (old == NULL) {
++elems_;
if (elems_ > length_) {
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
Resize();
}
}
return old;
}- 缓存的基础节点是
二级指针
在HandleTable这个哈希表实现里, 有个FindPointer方法用来查找此对象是否已存在, 并返回LRUHandle**, 代码如下:1
2
3
4
5
6
7
8
9
10
11// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];
while (*ptr != NULL &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
可见, 如果已存在节点, 则返回这个节点的LRUHandle**; 如果不存在, 返回的是可以保存这个LRUHandle*的地址.
- LRUCache缓存查找
如果缓存存在, 则将其放置到哑节点lru_的prev位置, 即最近使用节点, 相当于提升它的优先级, 便于下次快速查找; 如果不存在这个缓存, 返回NULL.小结
看完leveldb的缓存实现, 在实现思路上, 是传统的lru算法, 使用哈希表判重, 根据缓存的请求时间提升缓存的优先级. 里面的细节例如使用哈希值的前n位进行路由, 路由到2^n个独立的缓存区, 各个缓存区维护自己的mutex进行并发控制; 哈希表在插入节点时判断空间使用率, 并进行自动扩容, 保证查找效率在O(1).