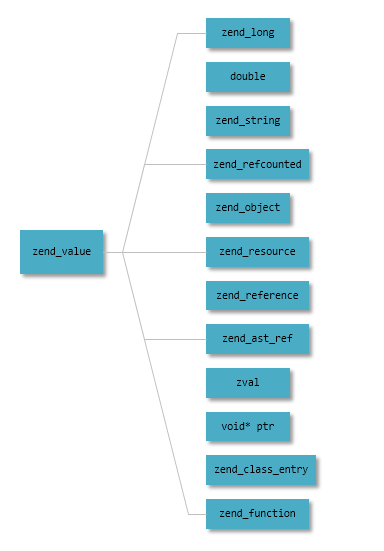
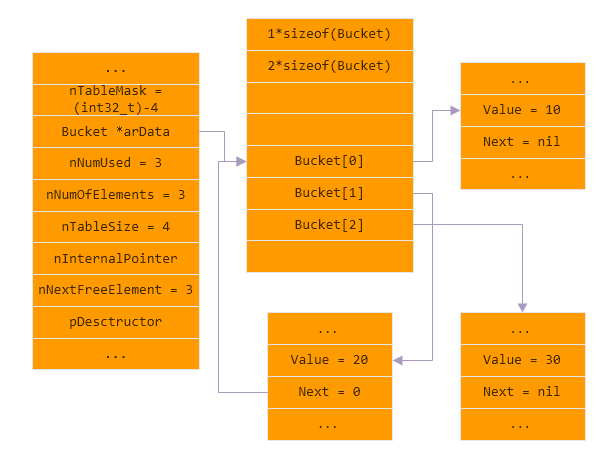
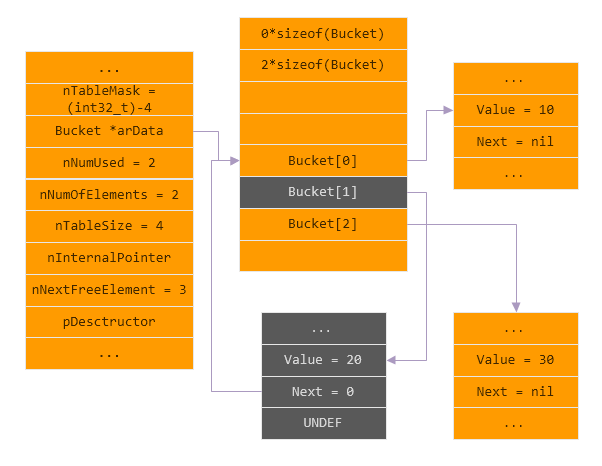
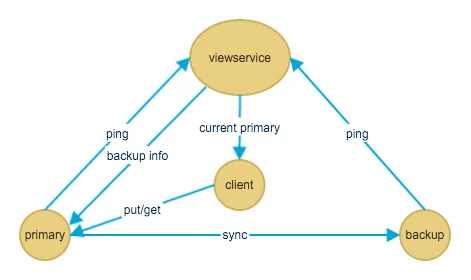
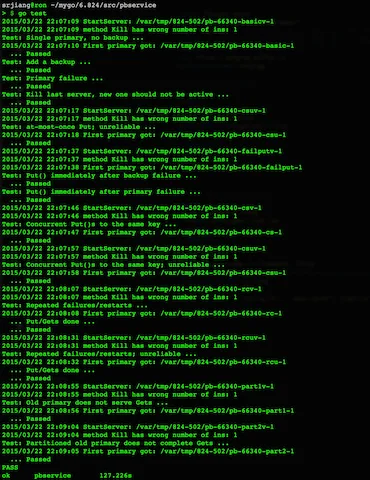
// zend_long.h /* This is the heart of the whole int64 enablement in zval. */ #if defined(__x86_64__) || defined(__LP64__) || defined(_LP64) || defined(_WIN64) # define ZEND_ENABLE_ZVAL_LONG64 1 #endif
// Return a pointer to slot that points to a cache entry that // matches key/hash. If there is no such cache entry, return a // pointer to the trailing slot in the corresponding linked list. LRUHandle** FindPointer(const Slice& key, uint32_t hash){ LRUHandle** ptr = &list_[hash & (length_ - 1)]; while (*ptr != NULL && ((*ptr)->hash != hash || key != (*ptr)->key())) { ptr = &(*ptr)->next_hash; } return ptr; }
// Accessors/mutators for links. Wrapped in methods so we can // add the appropriate barriers as necessary. Node* Next(int n){ assert(n >= 0); // Use an 'acquire load' so that we observe a fully initialized // version of the returned Node. returnreinterpret_cast<Node*>(next_[n].Acquire_Load()); } voidSetNext(int n, Node* x){ assert(n >= 0); // Use a 'release store' so that anybody who reads through this // pointer observes a fully initialized version of the inserted node. next_[n].Release_Store(x); }
// No-barrier variants that can be safely used in a few locations. Node* NoBarrier_Next(int n){ assert(n >= 0); returnreinterpret_cast<Node*>(next_[n].NoBarrier_Load()); } voidNoBarrier_SetNext(int n, Node* x){ assert(n >= 0); next_[n].NoBarrier_Store(x); }
private: // Array of length equal to the node height. next_[0] is lowest level link. port::AtomicPointer next_[1]; };
uint32_tNext(){ staticconstuint32_t M = 2147483647L; // 2^31-1 staticconstuint64_t A = 16807; // bits 14, 8, 7, 5, 2, 1, 0 // We are computing // seed_ = (seed_ * A) % M, where M = 2^31-1 // // seed_ must not be zero or M, or else all subsequent computed values // will be zero or M respectively. For all other values, seed_ will end // up cycling through every number in [1,M-1] uint64_t product = seed_ * A;
// Compute (product % M) using the fact that ((x << 31) % M) == x. seed_ = static_cast<uint32_t>((product >> 31) + (product & M)); // The first reduction may overflow by 1 bit, so we may need to // repeat. mod == M is not possible; using > allows the faster // sign-bit-based test. if (seed_ > M) { seed_ -= M; } return seed_; }