物理机部署
传统发布流程(以Java spring boot为例)
- 编译jar包
- 分发到服务器A,B,C
- 服务启动,监听到指定端口
- 配置负载均衡到已启动服务端口
- 服务发布成功
关于服务更新,为了实现滚动更新,可以让LB绑定的服务逐渐更新
传统更新流程
- 编译jar包
- 分发到服务器A,B,C
- 将服务器A从LB上解绑,更新服务器A上的服务
- 启动服务,通过健康检查和QA之后,将服务器A绑定到LB上
- 继续更新服务器B和C
- 服务完全更新成功
拓容流程
- 新增机器节点
- 启动jar包
- 将新节点注册到LB上
特点
- 单机端口有限,同一个服务如果在同一个服务器更新,需要不同的端口
- 动态更新LB
- 拓容成本高
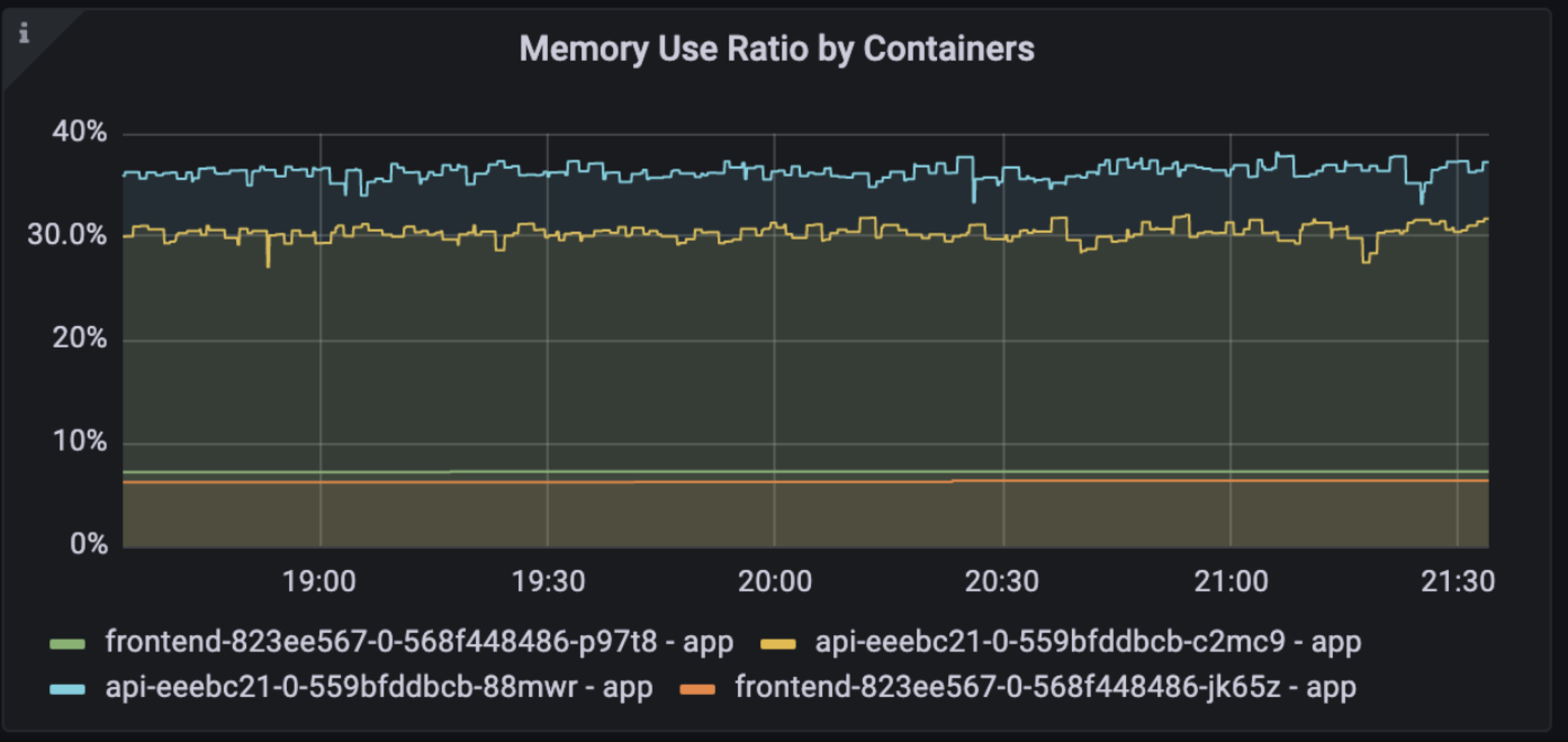
服务化部署(这里以kubernetes为例)
k8s发布流程
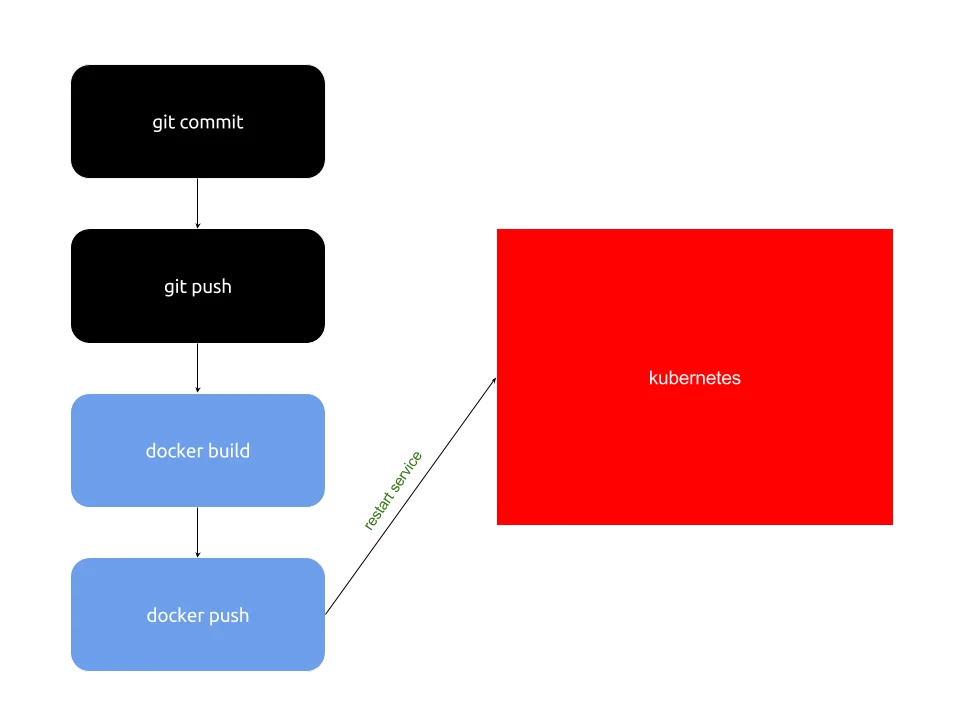
- 构建docker镜像
- 创建deployment和service,可以限制服务的CPU、Memory等资源,k8s寻找空闲节点启动服务
- 更新iptables将物理机上指定端口路由到VIP(虚拟服务IP)
- 绑定物理机端口到LB
k8s更新流程
- 构建docker镜像
- 更新deployment和service,k8s更新某个pod
- 轮流更新pod,直到所有pod更新完成
k8s拓容
- 寻找空闲节点启动服务,直到达到指定数量
特点
- 几乎无物理端口限制(k8s需要物理端口作为转发,默认为30000+,数量有限)
- 服务间通信,可以使用serviceName或者服务的VIP进行访问,内网访问更方便
- 虚拟化物理机资源,隔离物理资源的细节,资源控制如拓容、服务资源限制方便
Kubernetes vs Docker swarm
- 稳定性上,k8s上基于iptables的网络路由比docker swarm的网络更加稳定
- 配置性上,k8s比docker swarm要复杂,swarm采用manager-worker架构,由manager调度worker,docker 1.12以上对于swarm原生支持,方便启动集群,不过k8s在新版本之后也越来越易于配置
- 管理系统上,swarm比k8s的UI界面更友好,操作性更强
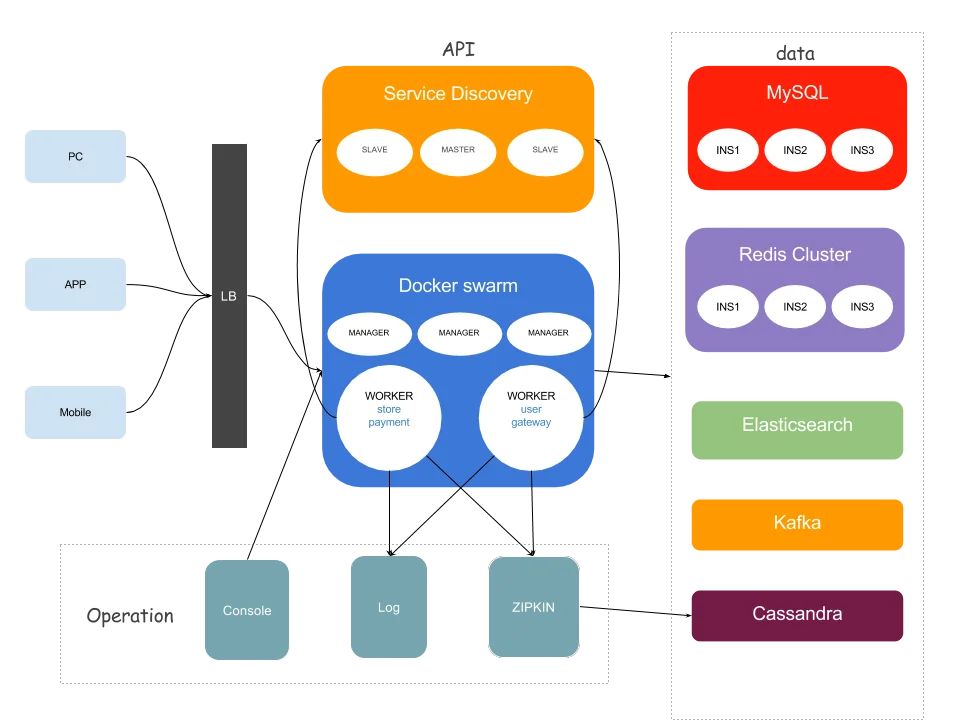
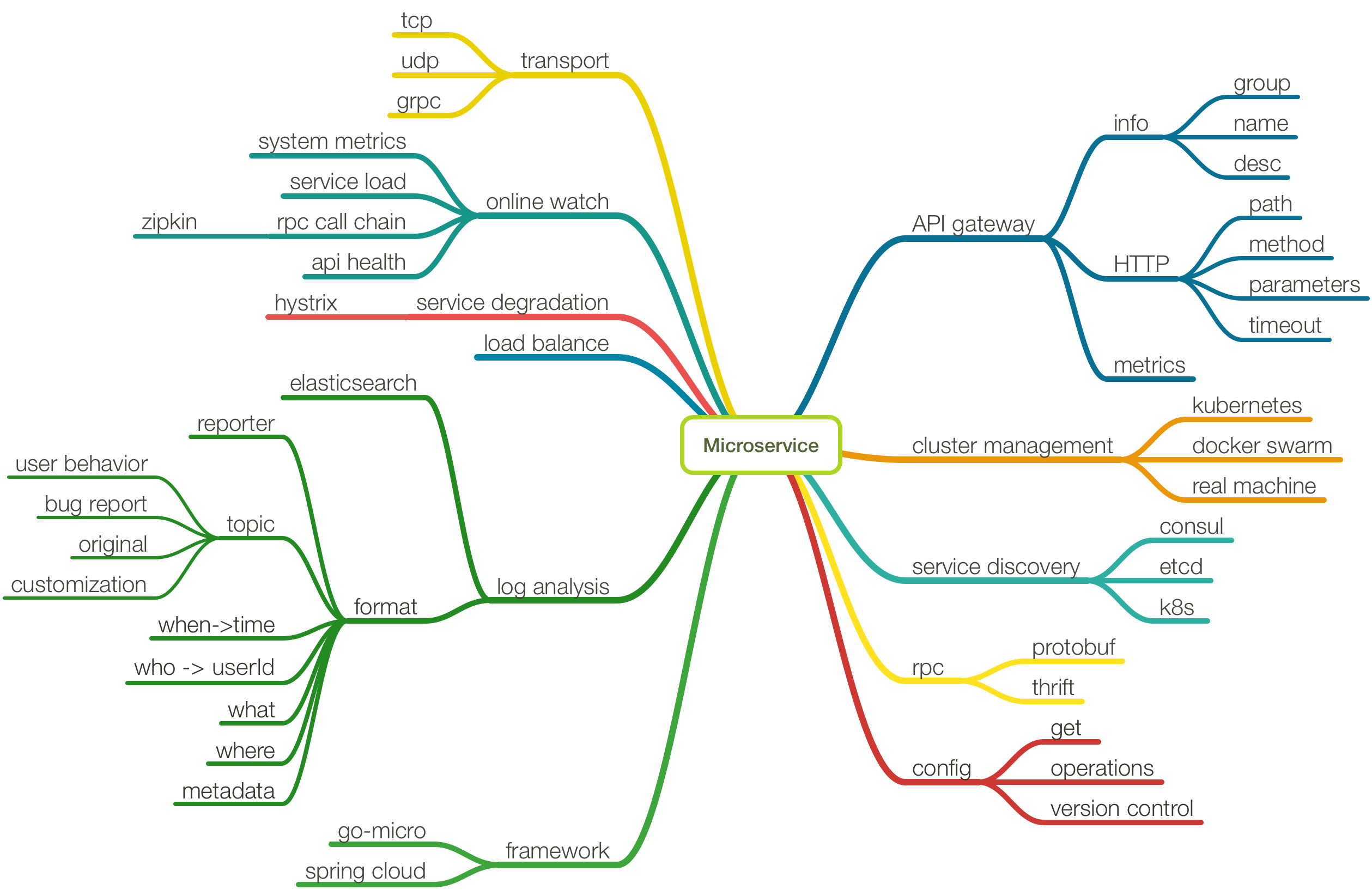
微服务架构下的应用
- 外部访问可以暴露gateway到LB上,外部通过访问LB进行访问
- 使用k8s或者swarm,服务间通信可以使用serviceName进行访问,也可以利用容器的IP,使用服务注册进行服务查询
- 自动拓容,当检测到服务的CPU和内存利用率升高,通过水平拓展,增加服务节点;服务压力减少后,逐渐减少服务节点数量