Anatomy of envoy proxy: the architecture of envoy and how it works
Envoy has become more and more popular, the basic functionality is quite similar to Nginx, working as a high performace Web server, proxy. But Enovy imported a lot of features that was related to SOA or Microservice like Service Discovery, Circuit Breaker, Rate limiting and so on.
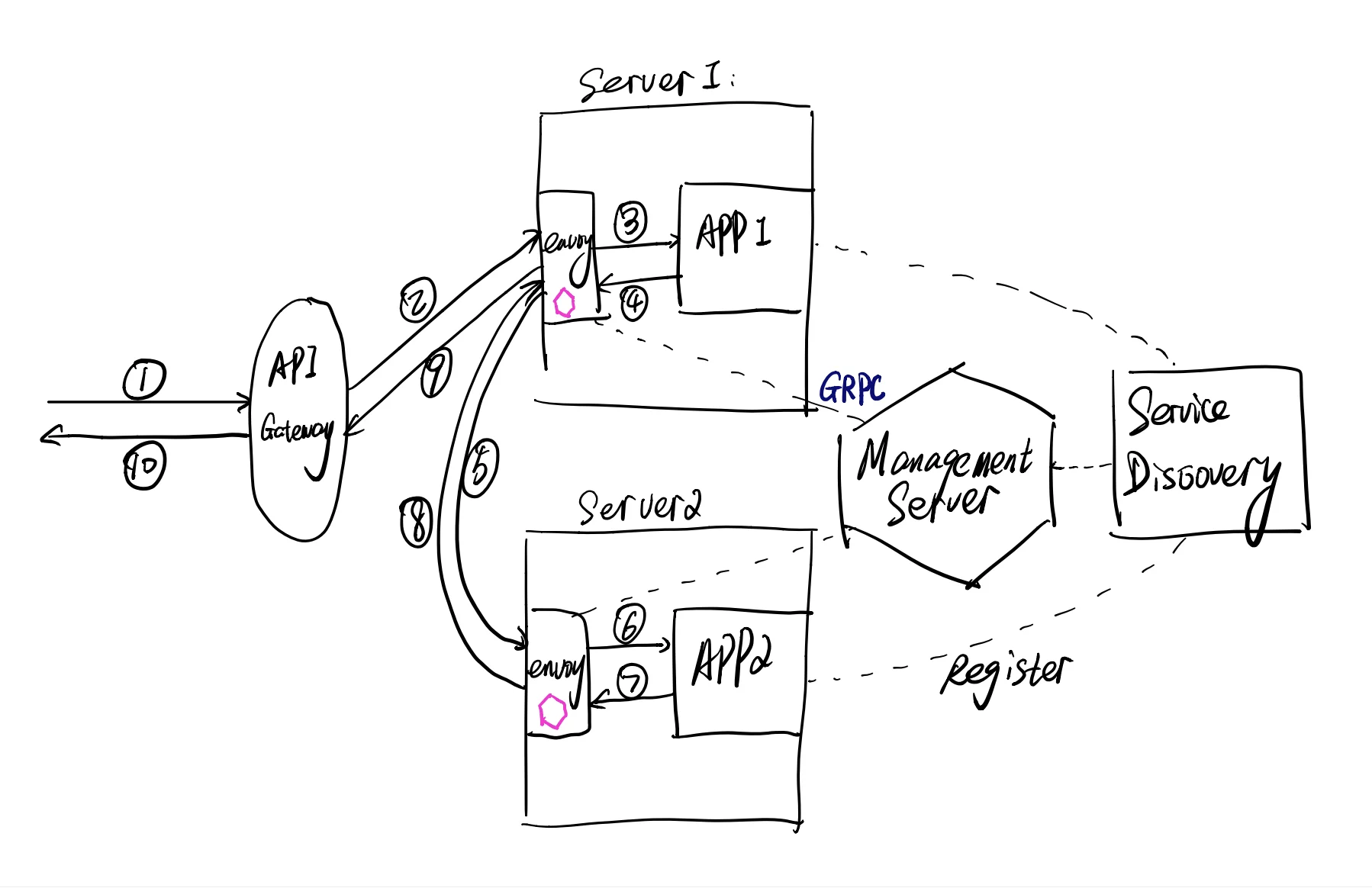
A lot of developers know the roles envoy plays, and the basic functionality it will implement, but don’t know how it organize the architecture and how we understand its configuration well. For me, it’s not easy to understand envoy’s architecture and its configuration since it has a lot of terminology, but if the developer knew how the user traffic goes, he could understand the design of envoy.