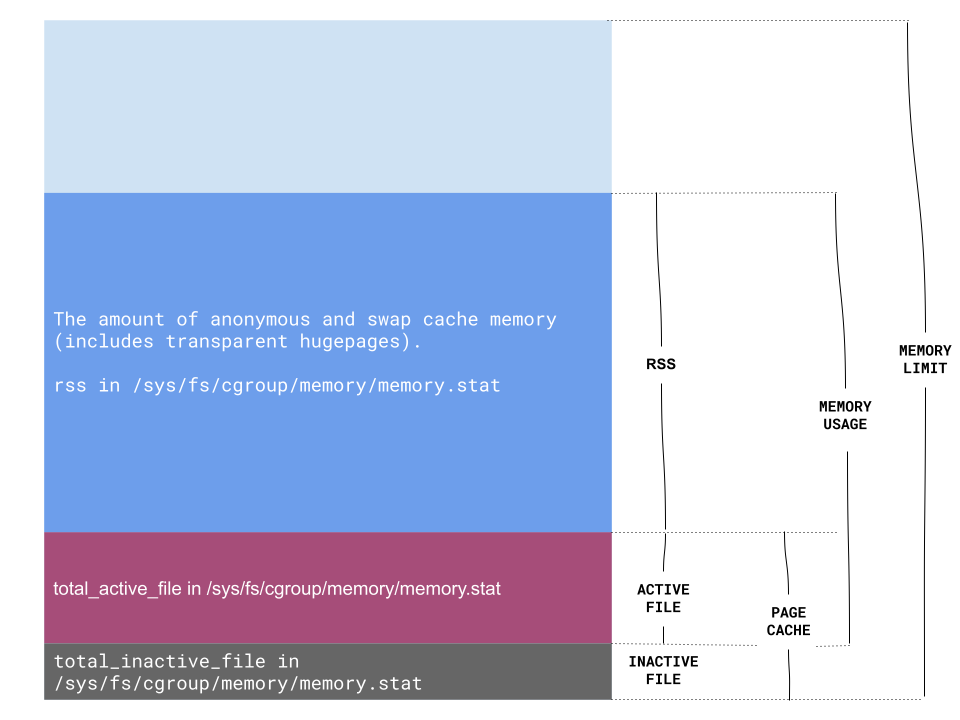
微服务实践二: 服务容错与降级
保证系统能稳定地运行在生产环境是第一要务,就算是服务质量下降,只要仍在工作,那就是万幸。
常见服务问题
服务超时
依赖的第三方服务因为某种不可抗力超时了?数据库慢查询拖垮了整个数据库?服务错误
某个服务挂了?服务负载高
突然陡增的访问量?
解决方法
限时
针对服务超时,可以通过超时控制保证接口的返回,可以通过设置超时时间为1s,尽快返回结果,因为大多数情况下,接口超时一方面影响用户体验,一方面可能是由于后端依赖出现了问题,如负载过高,机器故障等。某个互联网公司曾经说,当系统故障时,fail fast。fallback
有些情况下,即使服务出错,对用户而言,也希望是透明的,无感的,设置一些fallback,做一些服务降级,保证用户的体验,即使这个服务实际上是挂掉的,返回内容是空的或者是旧的,在此故障期间,程序员能赶紧修复,对用户几乎没有造成不良体验。电路熔断
这里的电路熔断是对于后端服务的保护,当错误、超时、负载上升到一定的高度,那么负载再高下去,对后端来说肯定是无法承受,好像和电路熔断一样,这三个因素超过了阈值,客户端就可以停止对后端服务的调用,这个保护的措施,帮助了运维人员能迅速通过增加机器和优化系统,帮助系统度过难关。
工具
Hystrix能保护客户端,服务降级,它的dashboard上有一句标语,defend your app,确实,当后端程序能对异常,超时,错误等进行处理,那么客户端能获得的数据能更加稳定统一,同时它也是对后端服务的保护,hystrix有上述的电路熔断机制和用户可以自定义fallback,对服务限时等功能。
hystrix运行流程可见How it works
以构建一个对内部RPC调用的HystrixCommand为例:
- 构建一个HystrixCommand用于RPC调用,设置超时时间为1s,fallback为返回空数据
- 如果缓存打开,结果优先从缓存中获取
- 如果电路被熔断,尝试fallback
- 如果并发量超过限制,尝试fallback
- 不然,运行实际的RPC调用,如果调用失败或者超时,尝试fallback
根据实际情况设置
hystrix的超时时间,fallback,并发量都可以根据需要封装的指令进行设置,可以说非常灵活,根据自己的具体业务进行合适的设置,能优化用户体验。
例如:文章列表API依赖的服务超时,可以通过服务降级拉取缓存中的旧数据进行返回,虽然即时性稍逊,但是起码用户能读到几分钟前的文章,在此期间,赶紧修复问题。